Core Concepts¶
1. Understanding Uncertainty in Machine Learning¶
This section explains what uncertainty means in machine learning, why it naturally arises in real-world problems, and why handling it correctly is essential for building trustworthy models. Probly provides tools to work with uncertainty in a structured and unified way.
Mini gallery (quick links)¶
Short, focused examples for the concepts in this section:
1.1 What Is Uncertainty?¶
In standard machine learning pipelines a model outputs a single prediction a class label, a probability, or a regression value. However this number does not tell us how confident the model actually is.
In machine learning, uncertainty refers to the degree of confidence a model has in its outputs. There are two fundamental types [HW21]:
Epistemic Uncertainty
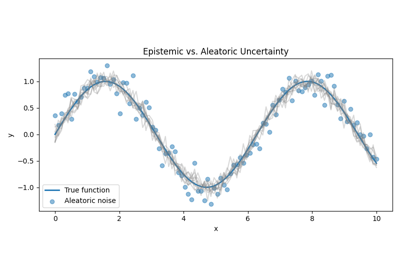
Uncertainty caused by lack of knowledge or insufficient training data. The model may never have seen anything similar before, for example a rare medical anomaly or an unusual object in autonomous driving. This uncertainty can be reduced with more or better data.

Aleatoric Uncertainty
Uncertainty caused by noise in the data itself. Labels may be ambiguous, sensors may be unreliable, or images may be blurry. This uncertainty cannot be eliminated simply by collecting more data.
Most classical ML models such as neural networks or random forests ignore both forms of uncertainty and return only a single output, often leading to overconfident predictions.
probly addresses this by offering unified tools to represent and quantify both epistemic and aleatoric uncertainty across different methods.
1.2 Sources of Uncertainty¶
Uncertainty appears naturally throughout the ML pipeline. Common sources include:
Limited or Biased Training Data
Small, imbalanced, or unrepresentative datasets cause poor generalization. When the model encounters unfamiliar examples, predictions become unreliable.
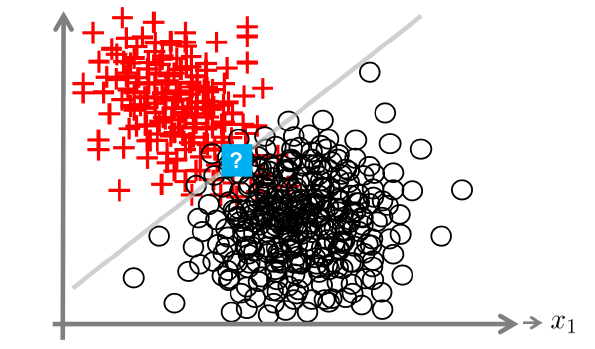
Out of Distribution Inputs
Inputs that differ significantly from the training data, such as new environments, novel objects, or corrupted images. Models often give confident but wrong predictions for such samples.
Label Noise and Ambiguity
Human annotators may disagree or produce inconsistent labels. Some domains, for example medicine or law, inherently contain subjective judgments.
Model Architecture Limitations
Certain architectures cannot express uncertainty well. A deterministic network without any probabilistic layers, for example, will always output a single best guess regardless of how unsure it is.
probly provides mechanisms to model all these uncertainty sources explicitly instead of ignoring them, aligning with the common epistemic/aleatoric framing [HW21].
1.3 Why Overconfidence Is a Problem?¶
Modern ML models are often overconfident. They produce strong high probability predictions even when they should be unsure. This causes serious issues in real world systems. Misjudging whether uncertainty is epistemic or aleatoric is a common driver of such overconfidence [HW21]:
Safety Critical Failures
A diagnostic model reporting 0.99 confidence despite being unsure.
An autonomous vehicle misreading a rare obstacle but still reacting as if it were certain.
Miscalibration
The model’s predicted probabilities do not match reality. For example predictions marked as 90 percent confident may be correct only 60 percent of the time.
Poor Decision Making
Downstream systems such as doctors, financial engines, or controllers may rely on predictions that look certain but are actually unstable.
Erosion of Trust
Professionals and regulators increasingly require models not only to provide predictions but also to communicate how reliable those predictions are.
probly directly addresses these challenges by offering consistent tools to express, compare, and act on model uncertainty, helping prevent dangerous overconfidence.
2. Representing Uncertainty¶
2.1 What Is an Uncertainty Representation?¶
An uncertainty representation describes the form in which a machine-learning model expresses not only its prediction but also its confidence in that prediction. Instead of returning a single label such as “cat,” an uncertainty-aware model produces additional information that reflects how sure or unsure it is about its output.
Such representations can take many forms, including probability distributions, repeated stochastic samples, raw logits, or evidence values for higher-level distributions. In practice, they may appear as sets of sampled outputs, vectors of class probabilities, parameters of a distribution, or structured intervals. All of these formats serve the same purpose: they quantify how uncertain the model is about its own prediction. [SKK19]
2.2 Common Representation Types¶
Dropout-based representations
Dropout-based representations arise when a model is evaluated multiple times with stochastic dropout activated. Each pass yields a slightly different output, and the collection of these outputs represents the model’s uncertainty.
Ensemble-based representations
Ensemble-based representations rely on several independently trained models whose predictions are combined; the variability across models expresses the epistemic uncertainty.
Evidential representations
Evidential representations work by predicting the parameters of a higher-order distribution rather than explicit samples. This allows the model to express both a belief and uncertainty about that belief through a single forward pass. This family of methods is closely related to evidential deep learning as introduced by Sensoy et al. [SKK19].
Bayesian sampling representations
Bayesian sampling representations describe uncertainty by drawing samples from distributions placed over the model’s weights, leading to sampled predictions that approximate the full predictive distribution.
Predictive distribution representations
Predictive distribution representations output parameters of a probability distribution or predictive intervals directly, allowing uncertainty to be expressed in a compact parametric form.
2.3 Why Representations Must Be Unified¶
Different uncertainty methods produce outputs that vary widely in dimensionality, structure, and meaning. Some provide many samples, others return explicit distribution parameters, and others supply intervals or evidence values. Without a unifying framework, these heterogeneous outputs cannot be compared or processed consistently.
Differences in shape, scale, interpretability, and semantics would make quantitative evaluation and benchmarking extremely difficult. A unified representation ensures that uncertainty estimates from different methods become compatible and can be analyzed within the same workflow.
2.4 How probly Standardizes Representations¶
Probly standardizes uncertainty by wrapping all forms of outputs into a single, unified representation object. This object provides a consistent interface for accessing samples, distribution parameters, evidence, or interval information, regardless of the underlying method that produced them.
Through this standardization, all uncertainty-quantification procedures, such as entropy calculations, variance-based metrics, scoring rules, or distance measures can operate on the same structure.
As a result, different uncertainty methods integrate seamlessly into one workflow, enabling fair comparison, reproducibility, and coherent processing across an entire pipeline.
3. Quantifying and Using Uncertainty¶
3.1 What is Uncertainty Quantification?¶
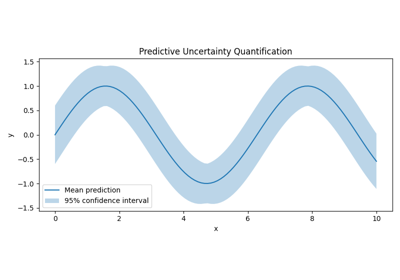
Models after being made uncertainty-aware can generate various forms of uncertainty representations (e.g., samples, credal sets, distributions over distributions). Uncertainty quantification means converting these representations into numerical measures of uncertainty.
Typical measures:
Entropy-based measures – Total entropy [Sha48] – Decompositions (e.g., upper/lower entropy) [HW21]
Variance-based measures – Variance of model predictions, e.g., in ensembles [LPB17a] – Variance under MC dropout [GG16a]
Scoring-Rule-Based Quantification – Proper scoring rules as uncertainty measures [GR07]
Wasserstein-Based Quantification – Distributional distances as uncertainty indicators [ACB17]
The distinction between the two main types of uncertainty follows the widely cited taxonomy introduced in [HW21]:
Aleatory uncertainty: inherent randomness and irreducible variability
Epistemic uncertainty: reducible uncertainty caused by lack of knowledge, limited data, or model misspecification
This distinction forms the basis of most modern uncertainty-aware machine learning approaches.
Thus, quantification = generating one or more meaningful numbers per example from an uncertainty representation.
3.2 Why Quantification is Important¶
Uncertainty quantification is essential for making uncertainty-aware models comparable, testable, and operable.
Reasons:
Comparing model behavior Different uncertainty-aware model families (Bayesian NNs, MC Dropout, Ensembles, Evidential Models, Conformal Prediction) can only be systematically compared when their uncertainty is expressed as measurable quantities [Abd21].
Detecting invalid predictions Quantified uncertainty enables detecting model failures and OOD data, a key idea in uncertainty-aware ML [HW21], [HG17].
Better decisions Selective prediction and selective rejection rely directly on uncertainty quantification [GEY17].
Without quantification, none of these downstream tasks would be feasible.
3.3 Downstream Tasks¶
The presentation introduces several practical applications of quantified uncertainty.
Out-of-Distribution (OOD) Detection Models should detect when an input is outside the training distribution. OOD detection is a core task in uncertainty research [Yan21], [HG17].
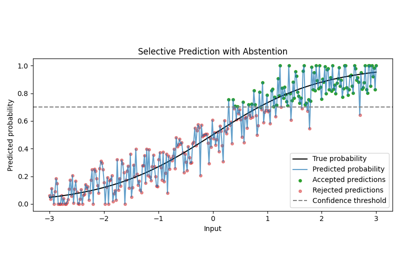
Selective Prediction / Confidence-Based Rejection The model may output “I don’t know.” This behavior is evaluated with accuracy–rejection curves [GEY17].
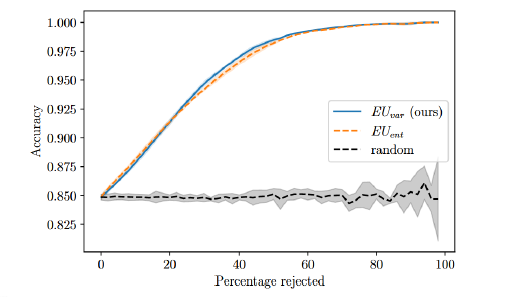
Accuracy–Rejection Curve illustrating the effect of rejecting uncertain samples.¶
Calibration Calibration ensures that predicted probabilities match empirical frequencies, an issue highlighted in modern deep learning models [GPSW17a].
Risk-Aware Decision Making Credal sets, distributional ambiguity, and pessimistic/robust reasoning are tools for risk-sensitive decisions [ACdCT14], [HW21].
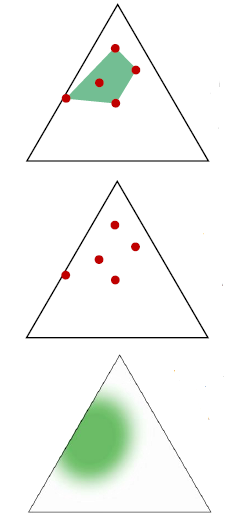
|
The figure shows three complementary ways to represent uncertainty within the probability simplex: top: a credal set capturing all admissible distributions middle: discrete samples describing a distribution over distributions bottom: a continuous density reflecting epistemic uncertainty through entropy. |
3.4 How everything is connected¶
1. Model Transformation A standard ML model is transformed into an uncertainty-aware version using techniques such as MC Dropout [GG16a], Bayesian Layers [Tra19], or Ensembles [LPB17a].
2. Uncertainty Representation The resulting model produces samples, credal sets, interval predictions, or distributions over distributions [HW21].
3. Uncertainty Quantification From these structures, entropy, variance, or scoring-rule-based measures are computed [GR07], [Abd21].
4. Downstream Tasks & Visualization OOD detection, selective prediction, calibration, and risk-aware decisions depend directly on quantified uncertainty.